SIMD(Single Instruction, Multiple Data):单指令多数据流,实质是通过数据并行来提高执行效率。
1. ARM 架构
1.1 ARMv1 - ARMv9

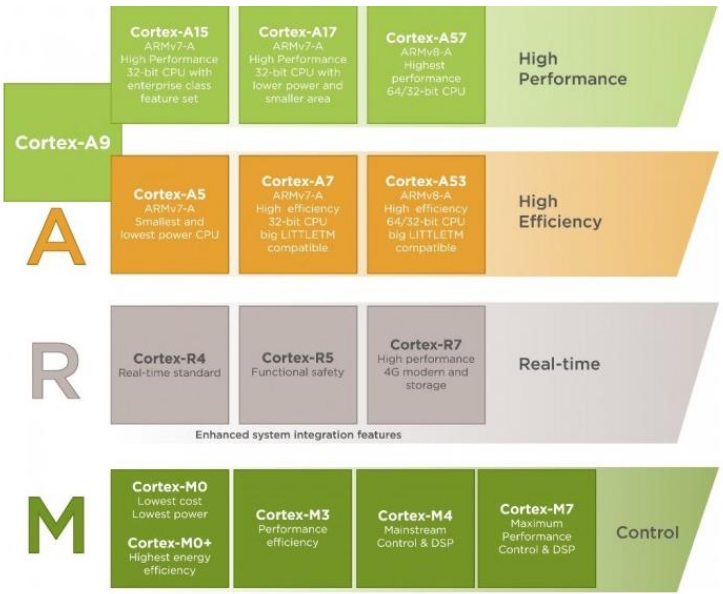
- 基于 ARMv7 版本的 ARM Cortex 系列产品由 A、R、M 三个系列组成,具体分类延续了一直以来 ARM 面向具体应用设计 CPU 的思路。
1.2 AArch64/AArch32
- ARMv8 的两种执行状态: AArch64/AArch32
- AArch64:Armv8-A 架构中引入的 64 位执行状态,执行 A64 指令,使用64bit的通用寄存器
- AArch32:兼容 Armv7-A 和先前的 32 位 Arm 架构的 32 位执行状态,执行A32/T32指令,使用32bit的通用寄存器
- ARMv8 支持浮点类型的除法向量操作,这是 ARMv7 没有的。另外 AArch64 还支持 double 类型的操作。
- Arm Compiler
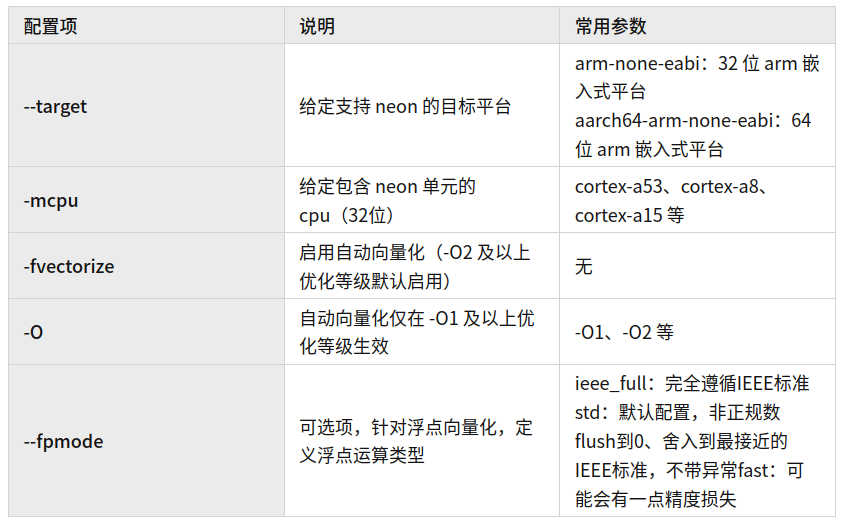
–target=aarch64-arm-none-eabi生成 AArch64 的可执行程序。默认使用 ARMv8-A target(处理器),也可使用 -mcpu 指定特定的 ARMv8 处理器。–target=arm-arm-none-eabi生成 AArch32的可执行程序。对 AArch32 而言,没有默认target(处理器),所以需要使用 -march 或者 -mcpu 来指定处理器,如:–target=arm-arm-none-eabi -mcpu=cortex-a53
2. SIMD
SIMD(Single Instruction, Multiple Data):单指令多数据流,实质是通过数据并行来提高执行效率。
2.1 x86 指令集

2.2 arm 指令集 - NEON
2.2.1 寄存器
向量寄存器用来存放向量数据,每个向量元素的类型必须相同。
向量寄存器根据处理元素的大小可以划分为 2/4/8/16 个通道。

AArch64 有 32 个 128bit 的向量寄存器,这些寄存器又可以划分为:
- 32 个 128bit 的 V 寄存器,V0~V31。
- 32 个 64bit 的 D 寄存器,D0~D31。
- 32 个 32bit 的 S 寄存器,S0~S31。
AArch32/ARMv7 有 16 个 128bit 的向量寄存器,这些寄存器又可以划分为:
- 16 个128bit 的 Q 寄存器,Q0~Q15。
- 32 个 64bit 的 D 寄存器,D0~D31。
- 32 个 32bit 的 S 寄存器,S0~S31。
2.2.2 汇编指令格式
{<prefix>}<op>{<suffix>} Vd.<T>, Vn.<T>, Vm.<T>
如:
:前缀名字,包括以下几类: - S/U/F/P:数据类型,分别为 有符号整型/无符号整型/浮点型/布尔型。
- Q:饱和(Saturating)计算。
- R:舍入(Rounding)计算, Rounding 操作等价于加上 0.5 之后再截断。
- H:折半(Halving)计算。
- D:翻倍(Doubling)算。
:具体的操作,例如 ADD,SUB 等等 :后缀名字,包括以下几类: - V:Reduction 计算。
- P:Pairwise 计算。
- H:结果只取每个通道的高半部分(High)。
- L/N/W/L2/N2/W2:数据长度的变化
- L/L2 :输出向量是输入向量长度的 2 倍,其中 L 表示输入寄存器的低 64bit 数据有效,L2 表示输入寄存器的高 64bit 数据有效。
- N/N2:输出向量是输入向量的 1/2 倍,N 表示输出向量只有低 64bit 有效,N2 则表示输出向量只有高 64bit 有效。
- W/W2:输出向量和第一个输入向量长度相等,且这两个向量是第二个向量长度的 2 倍,其中 W 表示第二个输入向量的低 64bit 有效,W2 表示第二输入向量的高 64bit 有效。
:单个通道的数据类型,8B/16B/4H/8H/2S/4S/2D,B 表示 8bit,H 表示 16bit,S 表示 32bit,D 表示 64bit
2.2.3 intrinsics 指令格式
2.2.3.1 向量类型格式
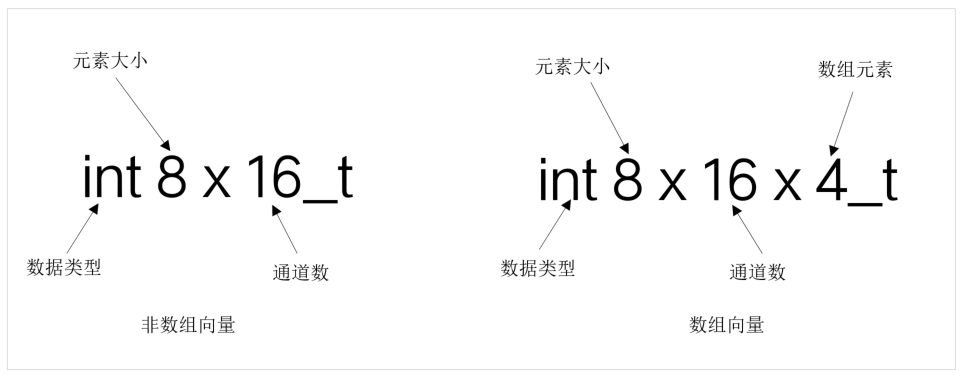
非数组向量:<type><size>x<number_of_lanes>_t
数组向量:<type><size>x<number_of_lanes>x<length_of_array>_t
- <type> 数据类型,如 int / uint / float。
- <size> 元素大小,如8/16/32/64。
通道数。 数组中元素个数。
2.2.3.2 NEON 内联函数格式
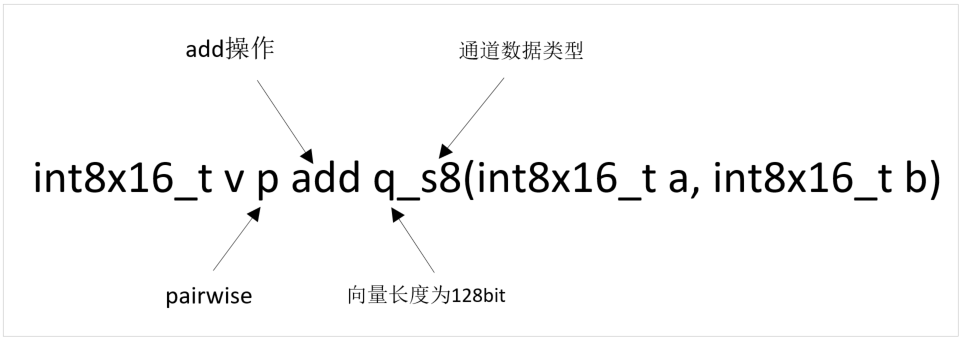
v<mod><opname><shape><flags>_<type>
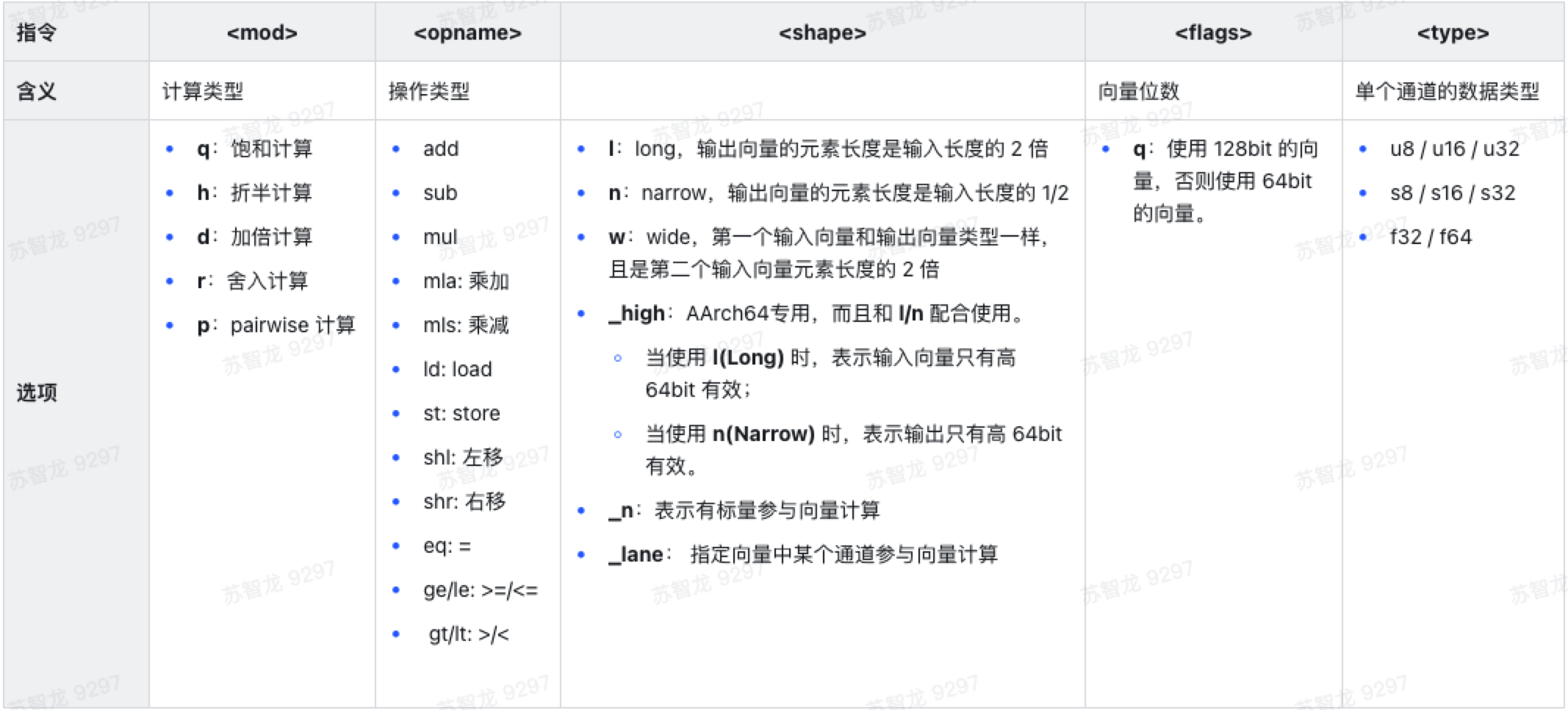
- 举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// a 加 b 的结果做饱和计算
int8x8_t vqadd_s8(int8x8_t a, int8x8_t b);
// a 减 b 的结果右移一位
int8x8_t vhsub_s8(int8x8_t a, int8x8_t b);
// a 乘 b 的结果扩大一倍, 最后做饱和操作
int32x4_t vqdmull_s16(int16x4_t a, int16x4_t b);
// 将 a 与 b 的和减半,同时做 rounding 操作, 每个通道可以表达为: (ai + bi + 1) >> 1
int8x8_t vrhadd_s8(int8x8_t a, int8x8_t b);
// 将 a、b 向量的相邻数据进行两两和操作
int8x8_t vpadd_s8(int8x8_t a, int8x8_t b);
// l:long,输出向量的元素长度是输入长度的 2 倍
uint16x8_t vaddl_u8(uint8x8_t a, uint8x8_t b)
// n:narrow,输出向量的元素长度是输入长度的 1/2
uint32x2_t vmovn_u64(uint64x2_t a)
// wide,第一个输入向量和输出向量类型一样,且是第二个输入向量元素长度的 2 倍
uint16x8_t vsubw_u8(uint16x8_t a, uint8x8_t b)

